404
Look Like You’re Lost
The link you followed probably broken or the page has been removed
Your partner in digital transformation. From scalable SaaS platforms to production-ready AI agents, we engineer the tech that drives your growth.
Musketeers Tech is an AI agent development company that builds custom autonomous agents to automate workflows, cut costs by up to 80%, and scale operations. From single-task agents to multi-agent orchestration, we deliver production-ready agentic AI systems.
Musketeers Tech provides web application development services that build high-performance SaaS platforms, enterprise portals, and progressive web apps. From React and Next.js frontends to scalable cloud-native backends: we deliver production-ready web applications that load in under 1 second.
Musketeers Tech provides MVP development services that validate your startup idea in 6-10 weeks, not 6 months. We build investor-ready Minimum Viable Products on production-grade architecture that scales from first user to Series A and beyond.
Musketeers Tech is a custom software development company that builds enterprise-grade applications tailored to your unique workflows. From legacy modernization to full-stack product engineering, we deliver scalable, secure software you own: with zero licensing fees.
Musketeers Tech provides generative AI development services: building custom LLM applications, RAG systems, and AI-powered automation that turn your proprietary data into competitive advantage. From proof of concept to production-grade deployment.
Musketeers Tech is a VR development company that builds immersive virtual reality training simulations, AR applications, 3D product experiences, and enterprise metaverse solutions: hardware-agnostic, optimized for 90fps+, and built on OpenXR standards.
Musketeers Tech provides fractional CTO services: executive-level technology leadership without the full-time salary. Strategy, architecture, team building, and investor-ready technical due diligence for startups and scaling companies.
Musketeers Tech provides technology strategy consulting that aligns your software, data, and infrastructure with business goals. We design the roadmap, vendor selection, and digital strategy so your technology drives revenue, not just cost.
Musketeers Tech is a digital transformation consulting firm that modernizes legacy systems, automates operations, and builds digital-first experiences: delivering measurable ROI within 90 days. From strategy to execution, we transform how enterprises operate.
Musketeers Tech provides cloud cost optimization services that cut your AWS bill by 20-40%: while improving performance and security. FinOps consulting, infrastructure automation, and Well-Architected reviews from AWS-certified engineers.
An AI avatar platform that delivers lifelike virtual conversations using GANs for real-time lip-sync, contextual NLP, and serverless GPU inference, generating $150K in revenue with 85% conversion rate increase and 1.2M impressions.
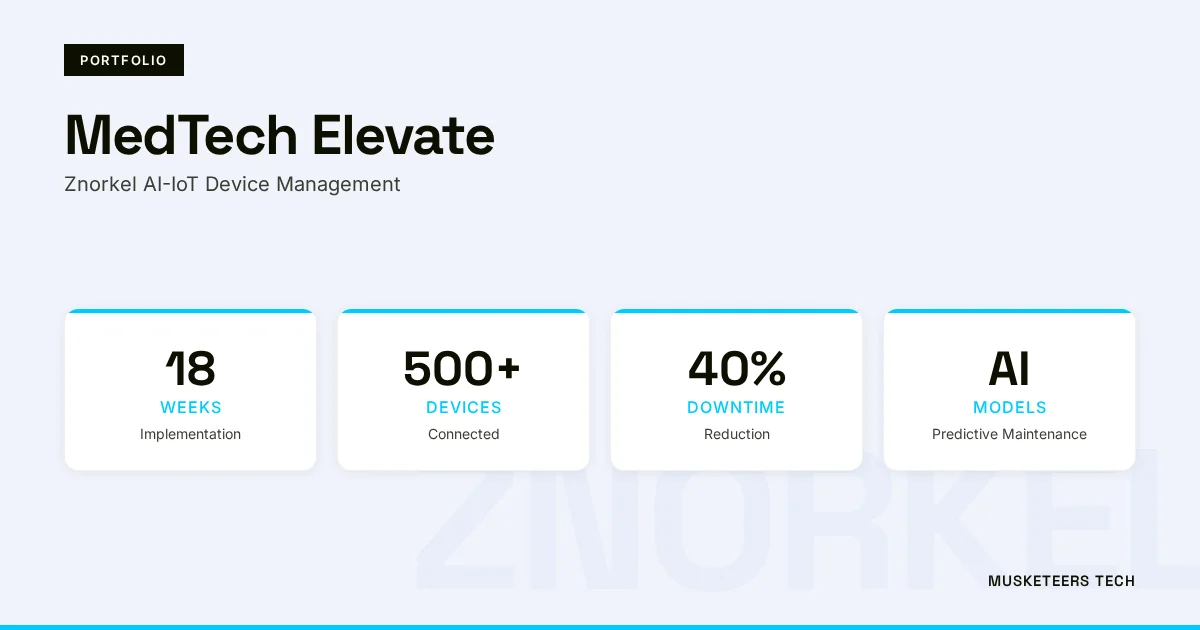
An AI-driven medical device lifecycle management platform built with Python, TensorFlow, and AWS IoT for Znorkel, achieving 40% reduction in device downtime, 35% operational efficiency improvement, and automated compliance reporting across 5,000+ lifecycle tasks.

A generative AI platform that transforms written content into immersive audio-visual experiences using neural text-to-speech and AI image generation, achieving 250K visual engagements, 30% conversion growth, and 60-second article-to-video processing.
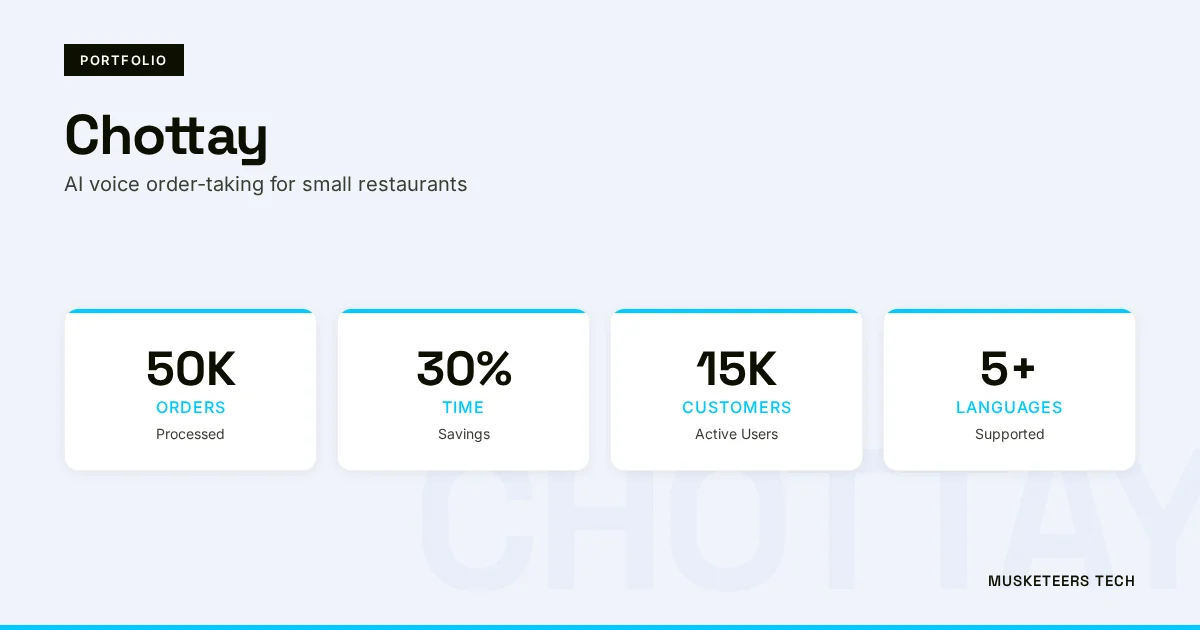
An AI-powered voice order-taking system for small restaurants using Flutter, OpenAI Whisper, and Firebase, processing 50K orders with 98% accuracy, saving owners 30% of their time, and serving 15K customers across 50 partner locations.

An AI-powered Chrome extension that generates personalized Upwork proposals using GPT-4 job description parsing, analyzing 100K bids, boosting win rates by 25%, and assisting in 50K successful proposals for freelancers.
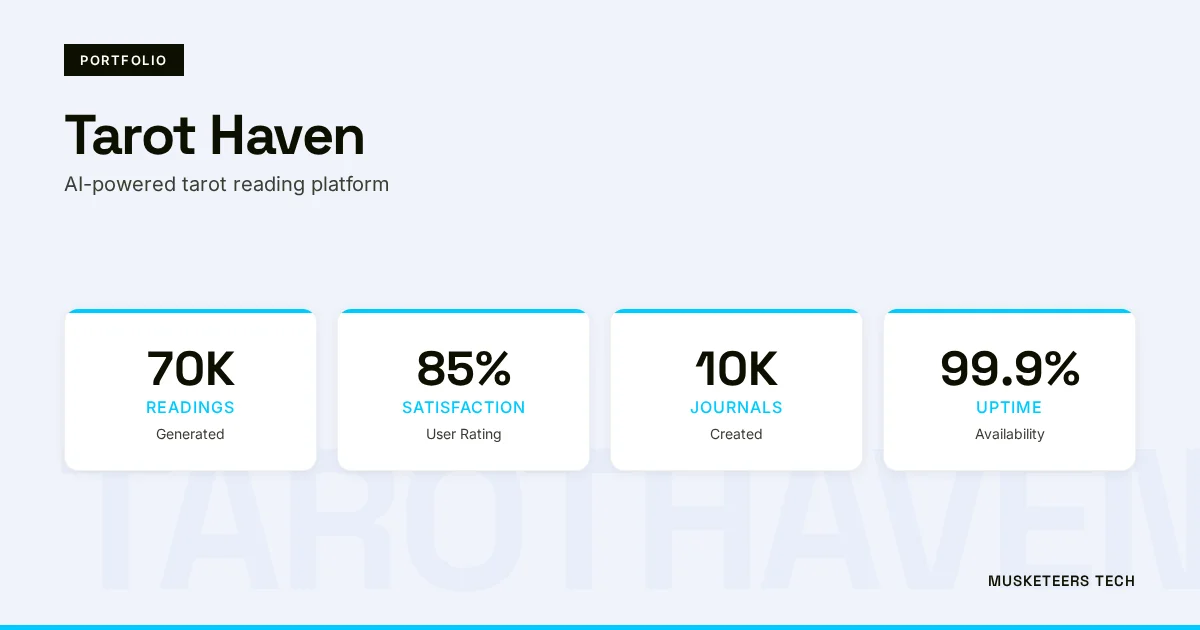
An AI-powered tarot reading platform built with Vue.js, Python, and GPT-4 that delivers deeply personalized interpretations, generating 70K unique readings with 85% satisfaction and 10K active spiritual journals.

A gamified real estate simulation game built on Unity for WebGL and mobile, teaching financial literacy through immersive property management gameplay, adopted by 50+ school districts with 500,000+ play sessions.
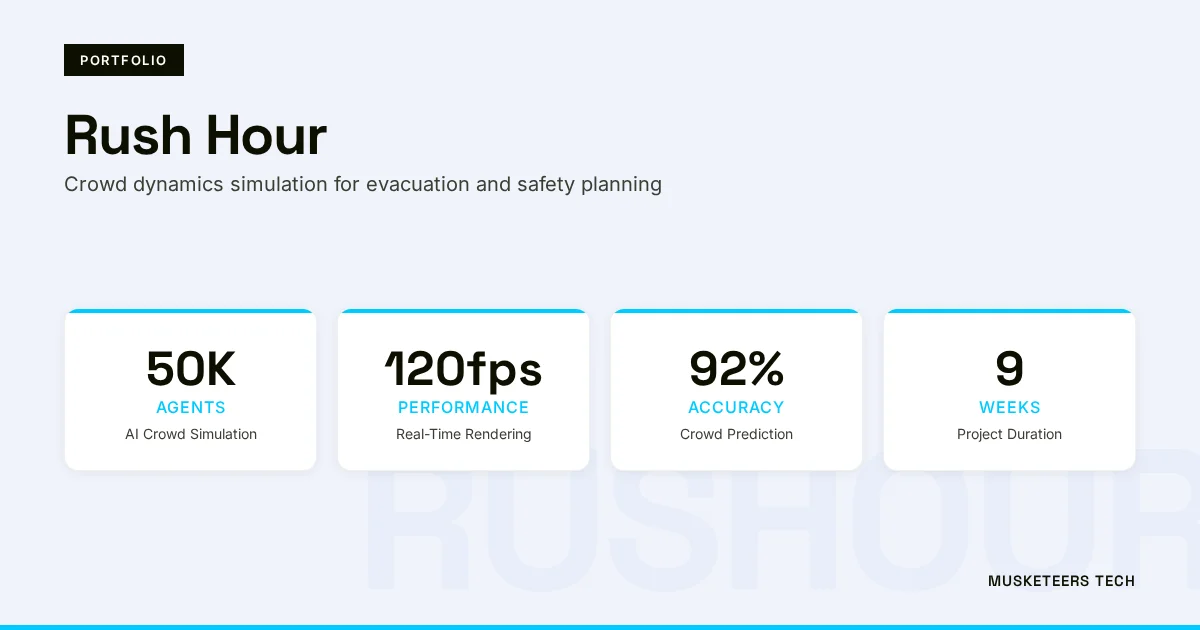
An advanced crowd simulation platform built on Unity DOTS, modeling 50,000 AI agents with unique behavioral profiles for evacuation planning and venue safety optimization, delivering 30% improved ingress/egress flow rates.
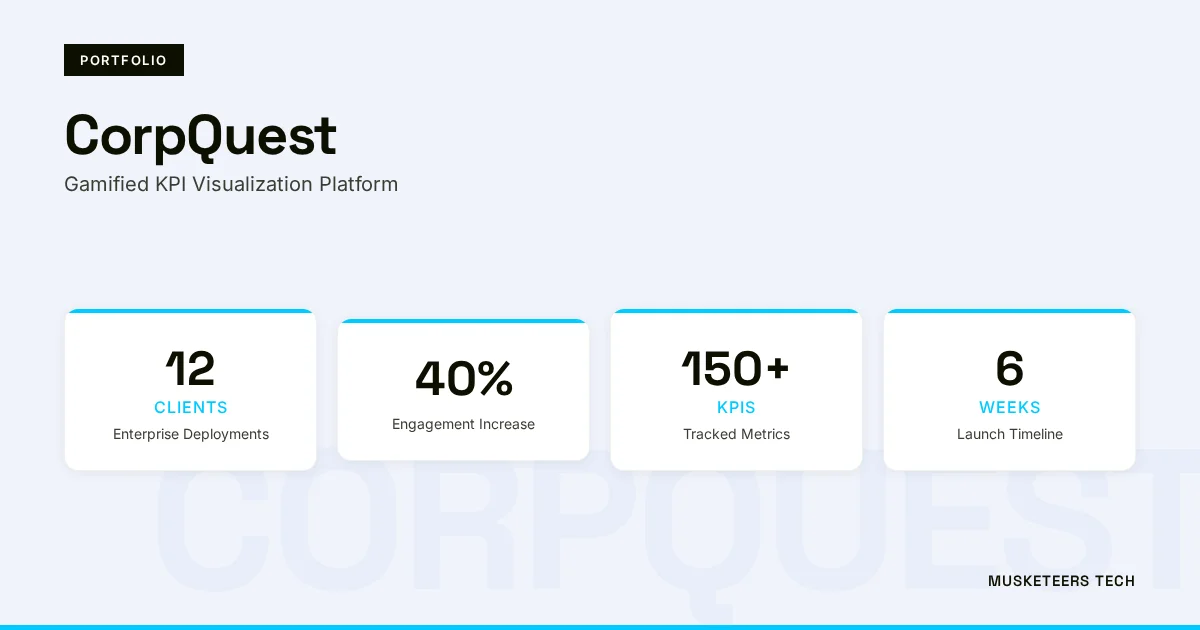
A 3D gamification platform built on Unity and WebGL that transforms corporate KPIs into an interactive 'Kingdom Map,' achieving 90% daily login rates and 60% better strategic understanding across 50,000 employees.
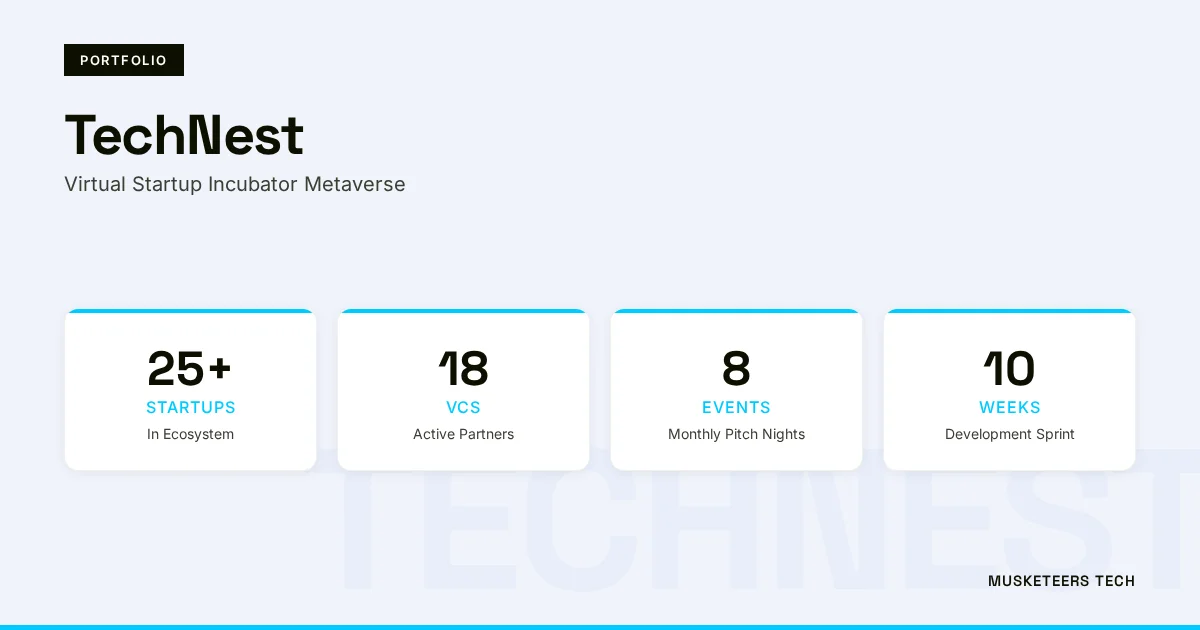
A persistent metaverse campus built on Unity with Photon Fusion and WebGL, connecting startups and VCs in a 3D virtual environment, facilitating $50M+ in seed funding and growing to 15,000 active monthly users across 90% non-hub geographies.
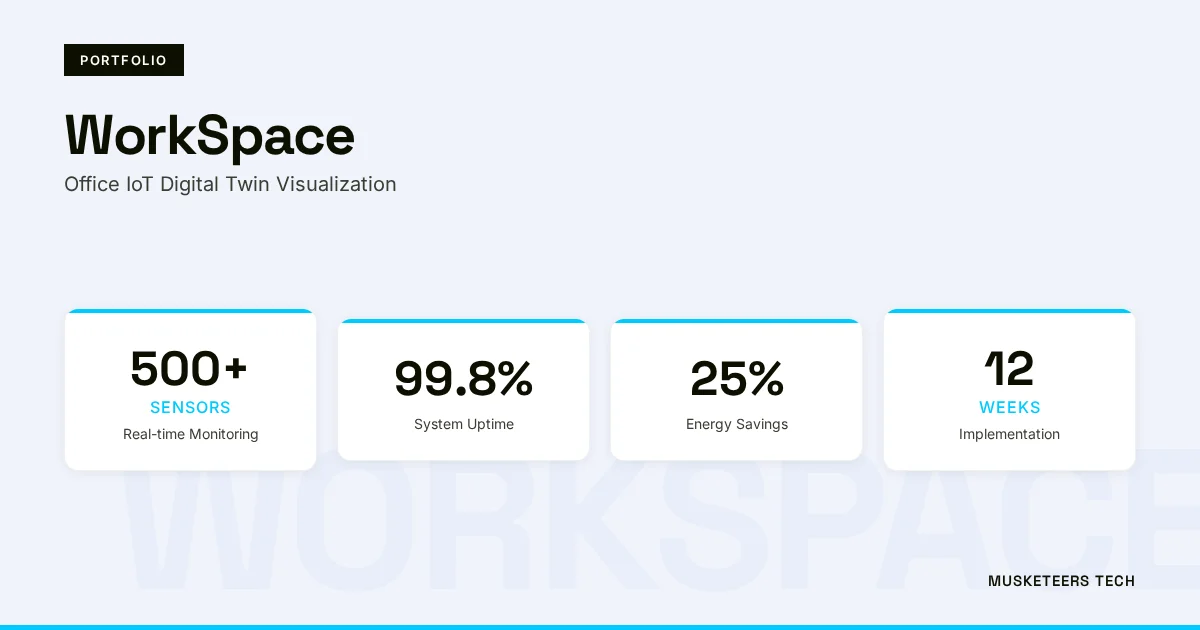
A real-time 3D digital twin of corporate headquarters built on Unity and AWS IoT TwinMaker, visualizing occupancy heatmaps and environmental data, delivering 30% lease reduction, 95% staff satisfaction, and Carbon Neutral certification.
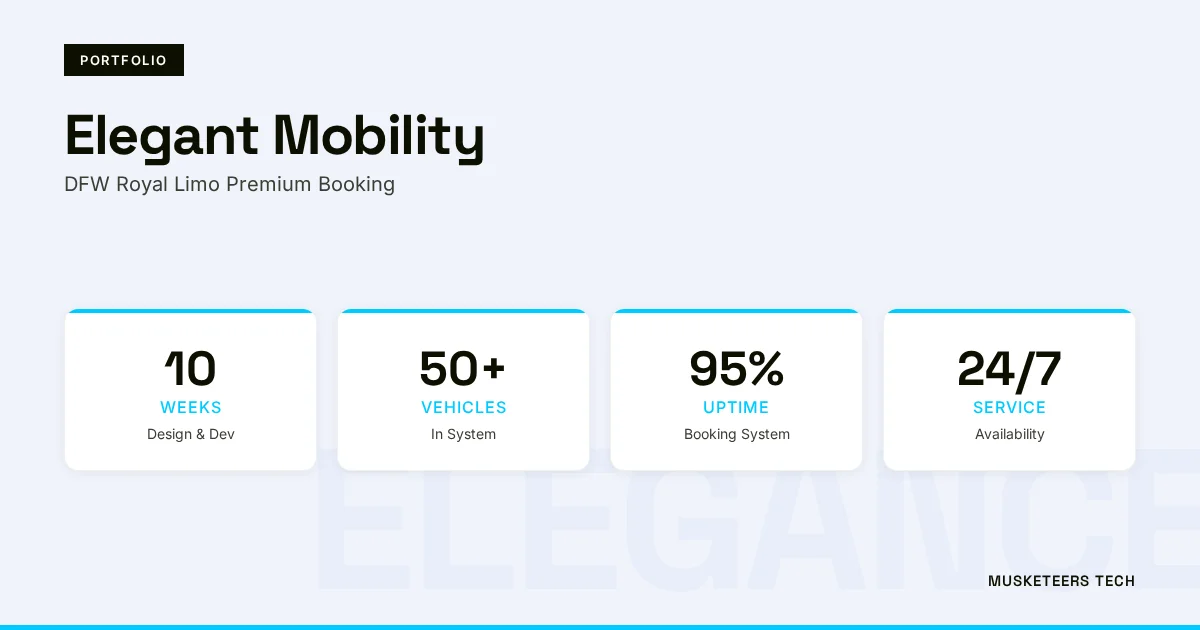
A luxury transportation booking platform that digitized DFW Royal Limo's operations with real-time fleet availability, dynamic pricing, and a premium UI, attracting 250K visitors, 40% booking conversion, and 2K monthly bookings.
The link you followed probably broken or the page has been removed
Let's turn your vision into a real, shipping product with AI, modern engineering, and thoughtful design. Schedule a free consultation to explore how we can accelerate your next app or platform.
Choose the best way to reach us
We'll call you back within 24 hours
We'll respond within 24 hours
But if your work is urgent, you can directly schedule a meeting with us below.
Pick a time that works best for you
$1.5M+
Musketeers shipped the Proof of Concept that turned a pitch into $1.5M.
