








ChatGPT 3.5 vs 4: Understanding the Upgrade
Choosing between ChatGPT 3.5 vs 4 sounds simple until you’re using it for real work like customer support, drafting policies, summarizing long documents, or writing production code. The headline is that GPT-4 is usually more accurate and better at complex reasoning than GPT-3.5, but it also costs more and can be slower depending on how you access it.
This guide breaks down the practical differences (not just marketing claims): what each model is good at, where the upgrade actually pays off, and how to test both models against your own prompts. We’ll also cover what “context window” really means for business workflows, and what to watch out for—like over-trusting browsing or shipping AI features without evaluation and guardrails.
If you’re a founder, PM, or operations leader trying to decide whether GPT-4 is worth it, this is the decision framework we use in real client work.
TL;DR
GPT-3.5 is faster and cheaper for low-risk, high-volume tasks. GPT-4 is stronger for complex reasoning, longer inputs, and customer-facing reliability. Many teams win with a hybrid: route simple work to GPT-3.5, escalate complex or high-stakes tasks to GPT-4.
What is ChatGPT 3.5 vs 4? (and what “upgrade” means)
ChatGPT is the product interface; GPT-3.5 and GPT-4 are underlying model families that generate the responses. In plain terms:
- GPT-3.5 is a fast, cost-efficient model that’s great for everyday drafting, brainstorming, and simpler Q&A.
- GPT-4 is generally stronger for multi-step reasoning, nuanced instruction-following, and tasks where mistakes are expensive (legal-ish summaries, technical analysis, complex coding).
Two clarifications that help teams avoid confusion:
- “GPT-4” isn’t a single static thing. OpenAI has released multiple GPT-4-class variants over time (e.g., “Turbo,” later “omni” variants). Product availability differs between ChatGPT plans and the API.
- Model choice should map to risk. If the output will be shown to customers, used for decisions, or turned into code - accuracy and robustness matter more than speed alone.
If you’re building workflows that rely on private company knowledge (policies, tickets, docs), pair your model choice with a knowledge approach like RAG or fine-tuning. See our practical walkthrough on training ChatGPT on your own data.
ChatGPT 3.5 vs 4 comparison: key differences that matter
Most “ChatGPT 3.5 vs 4 difference” discussions list features. What matters is how those differences show up in business outcomes: fewer retries, fewer wrong answers, and more reliable execution.
Here’s a practical comparison you can use when making a decision.
| Dimension | GPT-3.5 | GPT-4 | What it means in practice |
|---|---|---|---|
| Reasoning & complex tasks | Good for straightforward prompts | Stronger for multi-step tasks | GPT-4 tends to do better with ambiguity and constraints |
| Accuracy / hallucinations | More likely to confidently guess | Generally more factual (still not perfect) | Fewer “looks right but wrong” outputs reduces rework |
| Context handling | Shorter conversations/documents | Better at long inputs and coherence | Helps with long tickets, specs, meeting notes |
| Multimodal inputs | Typically text-only | Can support image input in supported versions | Useful for screenshots, UI review, document images |
| Speed & cost | Faster and cheaper | Usually more expensive | GPT-3.5 is ideal for high-volume low-risk automation |
| Best fit | Drafting, summaries, simple bots | Coding, analysis, customer-facing reliability | Match model to business risk |
For OpenAI’s published benchmark claims, see the GPT-4 materials and safety documentation (e.g., the GPT-4 page and system card references on OpenAI’s site): https://openai.com/index/gpt-4/
Context window & “memory”: what it really means
The context window is how much text the model can consider at once (your prompt + previous messages + system instructions + retrieved knowledge). A larger context window can help when you need to:
- Summarize a long policy and answer questions about it
- Analyze a long error log or multi-file code snippet
- Keep multi-step instructions consistent (format + constraints + tone)
In plain English: if GPT-3.5 feels like it “forgets” a requirement halfway through a workflow, GPT-4-class models tend to hold the thread better—especially when prompts are long or layered.
Multimodal inputs: why it changes workflows
For teams working with screenshots, forms, diagrams, or UI issues, multimodal support can be a major productivity boost. Examples:
- Support: “Here’s a screenshot of the error. What’s likely happening?”
- Product: “Review this UI for accessibility issues and missing states.”
- Engineering: “Here’s a chart + notes—summarize anomalies and propose hypotheses.”
If multimodal is central to your workflow, GPT-4-class models are the practical choice.
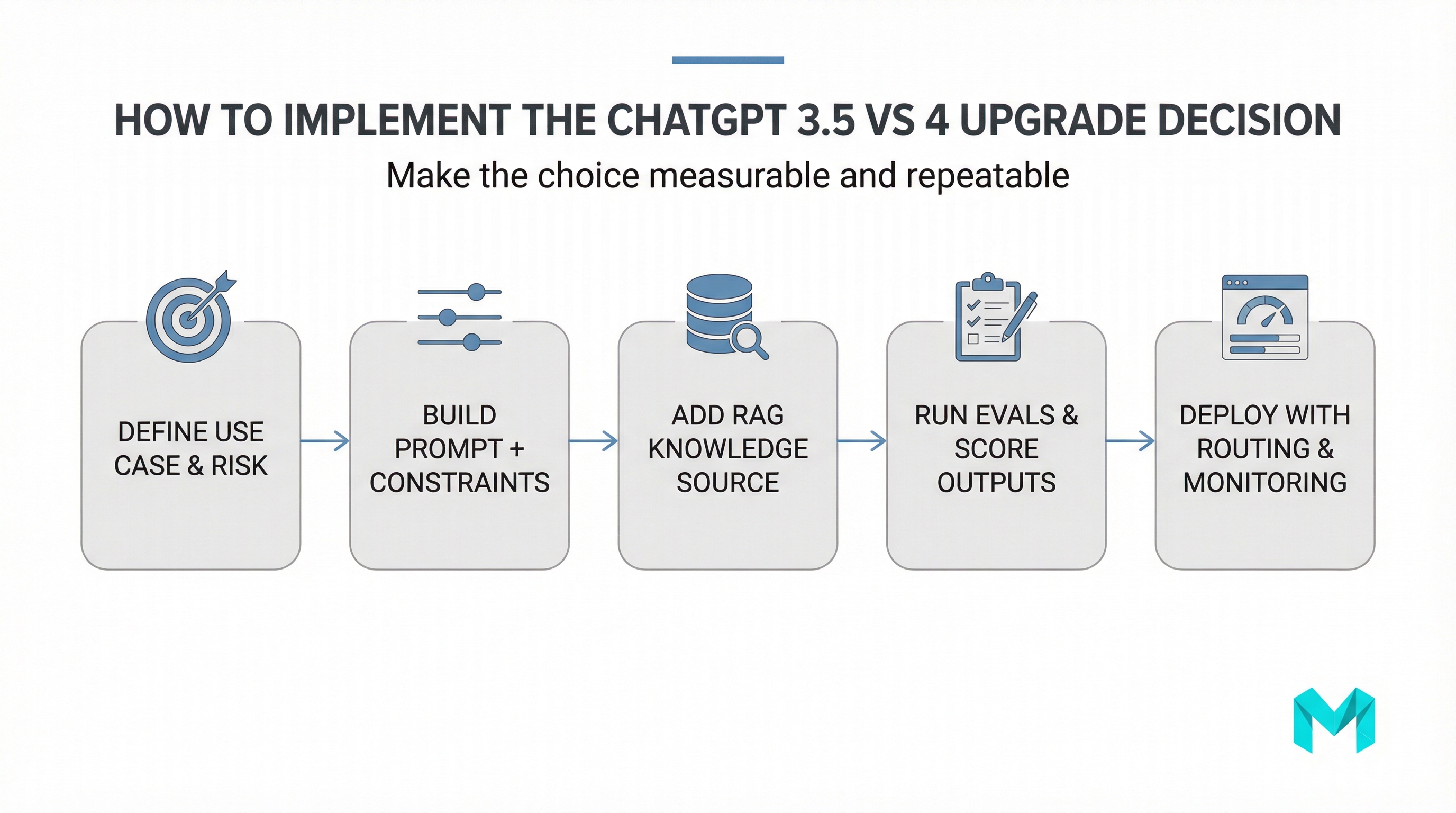
Pricing & access: the real-world cost of GPT-4 vs 3.5
Pricing is often the deciding factor, and it depends on whether you’re using ChatGPT plans or the API:
- ChatGPT (consumer/business plans): GPT-3.5 is typically available on free tiers; GPT-4 access is generally tied to paid plans (and may have usage limits).
- API usage: You pay per token (input/output). GPT-4-class models cost more per token than GPT-3.5-class models, so high-volume use cases can get expensive quickly.
Pricing and rate limits change. Always verify current pricing on OpenAI’s official page: https://openai.com/chatgpt/pricing/
A practical budgeting tip: many teams use a two-tier strategy:
- Default to GPT-3.5 for low-risk, high-volume steps (classification, routing, first drafts).
- Escalate to GPT-4 when the task crosses a “risk threshold” (customer-facing answers, compliance language, complex code, executive summaries).
Is the upgrade worth it for business teams? (Decision checklist)
This is the biggest gap in most competitor content: teams don’t just want “what’s different,” they want “should we upgrade?”
Use this quick checklist. If you answer “yes” to 3+ items, GPT-4 is usually worth testing first.
- Fewer retries to get an acceptable answer (time saved matters).
- Better performance on multi-step reasoning (planning, analysis, tradeoffs).
- More reliable outputs for customer-facing or high-stakes content.
- Stronger handling of long documents (policies, specs, contracts, playbooks).
- Better coding help (debugging, refactoring, tests, system design).
- Multimodal workflows (screenshots, images, charts) in supported variants.
GPT-3.5 is usually enough if you need:
- Fast drafts, brainstorming, lightweight summaries.
- High-volume automation where errors are caught downstream (e.g., internal routing).
- Cost control above all else.
A simple ROI way to think about it:
Quick ROI heuristic
If GPT-4 reduces your team’s “prompting time” by even 5–10 minutes per knowledge worker per day, the upgrade can pay for itself quickly. If you’re processing thousands of low-risk requests, GPT-3.5 might be the better default.
For business analysis workflows where prompt quality matters more than model choice, see these ChatGPT prompts for business analysis.
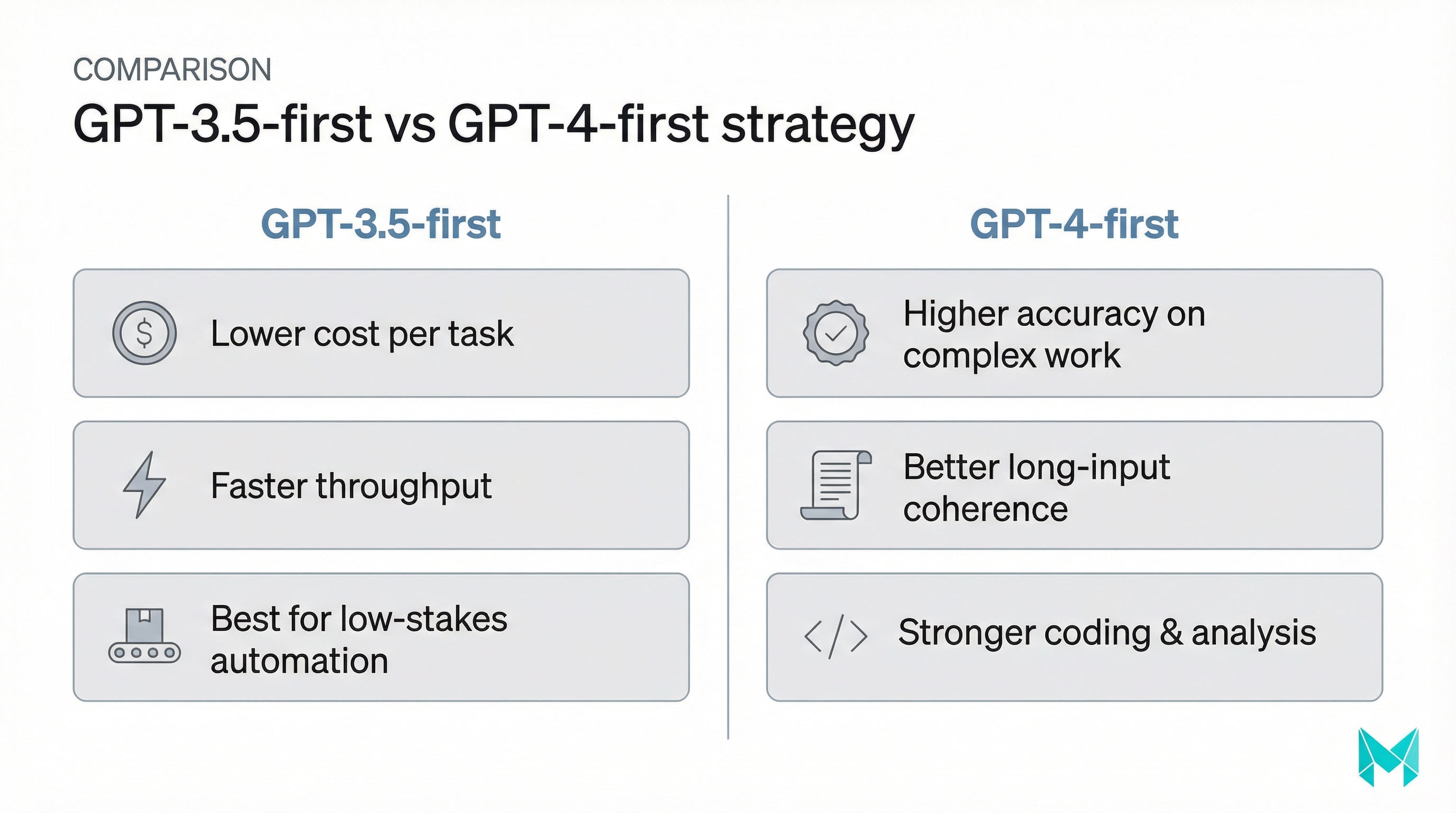
ChatGPT 3.5 vs 4 for coding: where the difference shows up
The keyword “chatgpt 3.5 vs 4 for coding” is popular because coding is where model quality becomes obvious fast.
In real engineering workflows, GPT-4-class models tend to do better at:
- Following multi-constraint requirements (edge cases, style, performance)
- Suggesting test cases (not just code)
- Debugging with hypotheses + verification steps
- Refactoring while preserving behavior
A simple evaluation rubric you can run this week
Pick 5 prompts from your real work and score each model 1–5:
- Correctness (does it compile/run; is it factually right?)
- Completeness (did it cover edge cases and constraints?)
- Explainability (can a human trust and verify it?)
- Format adherence (JSON, Markdown, code style, etc.)
- Time-to-usable-output (including retries)
Run the same prompts through GPT-3.5 and GPT-4 and average the scores. This turns “feels better” into a measurable decision.
If you’re building AI features into a web product, you’ll also want strong UX and guardrails around generated content. Related read: practical uses of AI in web development.
Tools & workflows to get better results (regardless of model)
Even GPT-4 can fail if your workflow is weak. These practices improve reliability across both models:
- Use a system message + structured output: Define role, boundaries, tone, and output format.
- Add retrieval (RAG) for company truth: Don’t rely on the base model to “know” your internal policies.
- Implement evals before you scale: Store prompts, outputs, and human ratings to catch regressions.
- Add safety guardrails: Redact PII, handle refusals, enforce safe completion patterns.
- Route by complexity: Use GPT-3.5 for triage/classification; GPT-4 for resolution/explanations.

If you want to go beyond chat and build agentic workflows (tools, actions, automations), that’s where architecture matters as much as the model.
Frequently Asked Questions (FAQs)
For complex work, ChatGPT-4 is typically better at multi-step reasoning, long context handling, and instruction-following. For simple drafting or quick Q&A, GPT-3.5 can feel good enough and faster, so better depends on task complexity and risk.
How Musketeers Tech Can Help
If you’re deciding between GPT-3.5 and GPT-4 because you want repeatable business results (not just demos), Musketeers Tech can help you implement the full system: model selection, prompt engineering, retrieval, evaluation, and production-grade guardrails.
We typically start by mapping your workflows (support, sales ops, product docs, engineering) to a risk/volume matrix, then implement a cost-efficient routing strategy—often using GPT-3.5 for high-volume steps and GPT-4 for high-stakes reasoning. From there, we add RAG so the assistant answers from your real knowledge base, and set up evals to keep quality stable over time.
We’ve built AI-driven products such as BidMate (AI assistant workflows) and Chottay (AI order-taking), and we can apply the same production discipline to your internal copilots or customer-facing assistants.
Generative AI Application Services
Design, build, and scale AI features with RAG, evaluations, and guardrails.
AI Agent Development
Agentic workflows that plan, call tools, and automate tasks safely.
Final Thoughts
The ChatGPT 3.5 vs 4 decision is ultimately a tradeoff between cost/speed and capability/reliability. GPT-3.5 is a strong default for lightweight drafting and high-volume automation. GPT-4 is typically the better choice when the work involves long context, nuanced instructions, complex reasoning, or customer-facing outputs where errors are expensive.
The fastest way to make the right call is to stop debating in the abstract and run a small evaluation: take 5 real prompts from your team, score both models, and measure time-to-usable-output. Pair that with a routing strategy and guardrails, and you’ll get the best of both worlds—lower costs without sacrificing quality.
Need help with model selection or building a production AI assistant? Check out our AI agent development or explore our recent projects.
Last updated: 03 Feb, 2026